T5
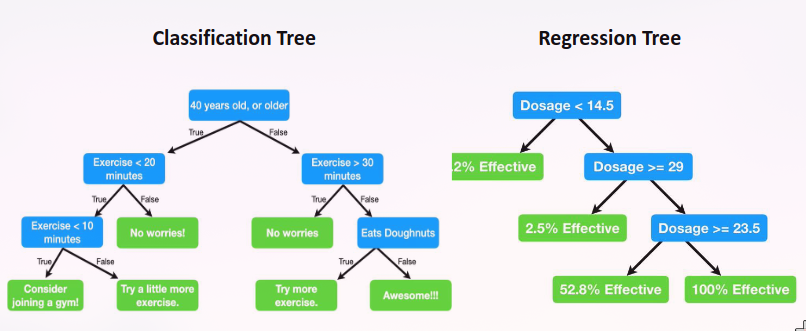
Classification Trees
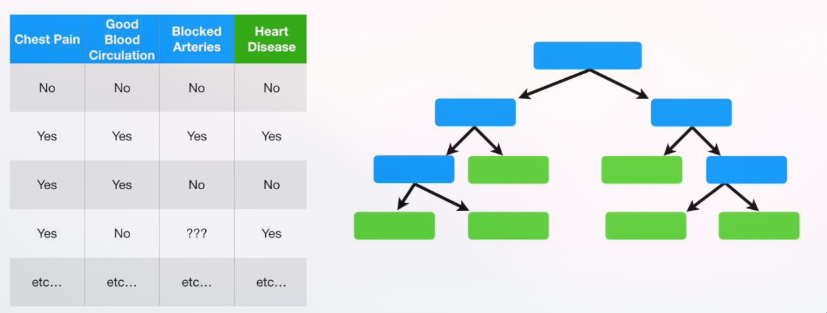
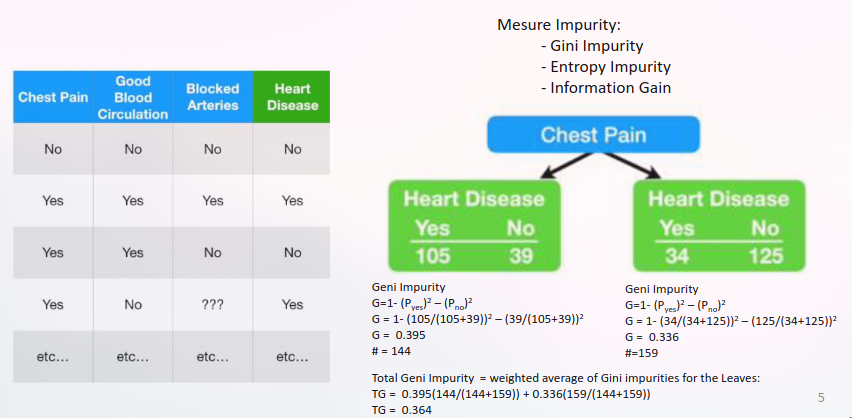
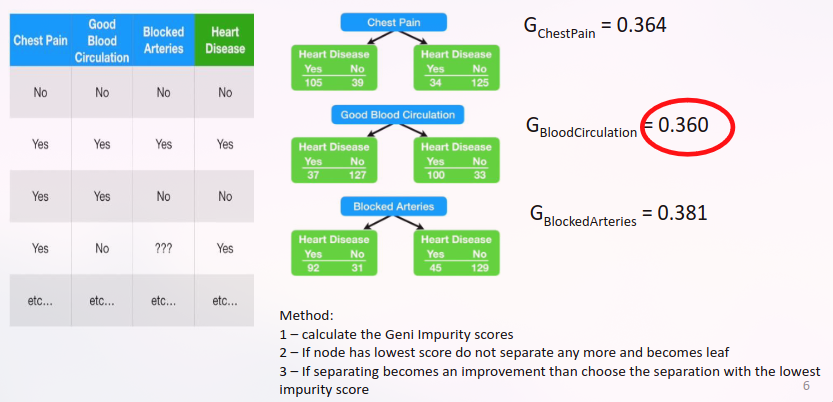
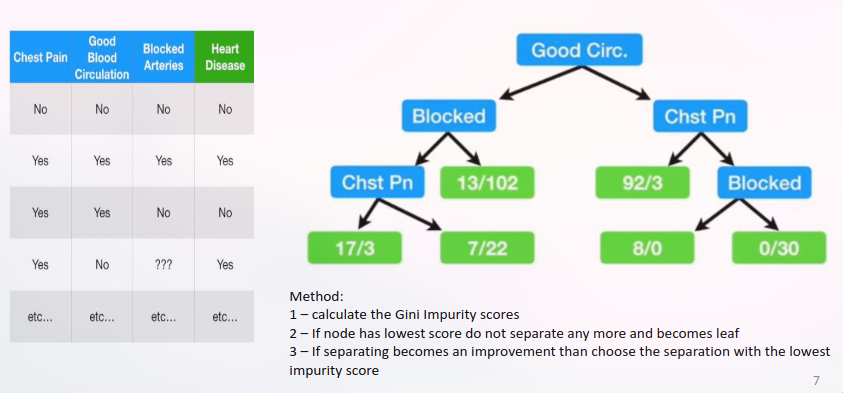
Continuous attributes

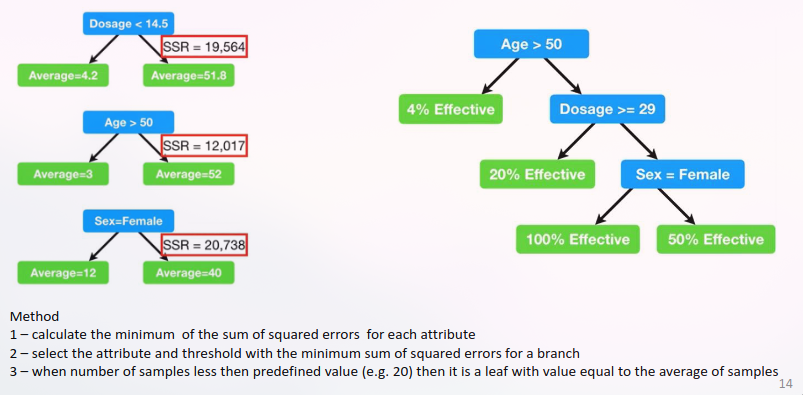
Regression Trees
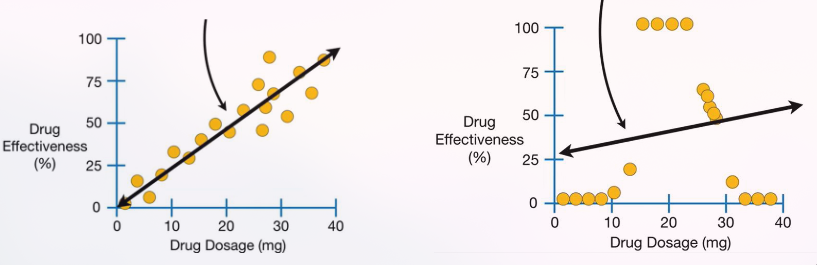

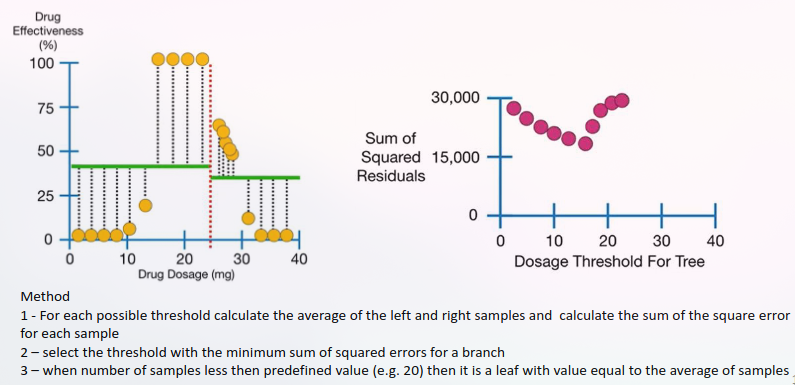
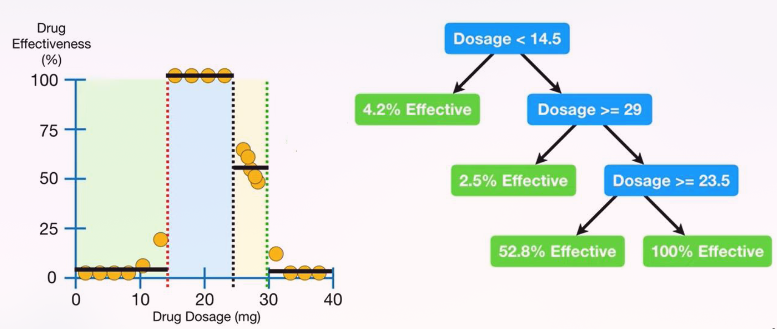
Multiple attributes

Pruning
A decision tree will always overfit the training data if we allow it to grow to its max depth.
Pre-prunning (early stopping):
-
min_sample_split is the minimum no. of sample required for a
split.

-
*min_sample_leaf *on the other hand is basically the minimum no.
of sample required to be a leaf

Post-prunning (after perfect training):
- Assign a maximum depth to a tree

- Pruning starts with an unpruned tree, takes a sequence of subtrees (pruned trees), and picks the best one through cross-validation.
- Cost complexity pruning generates a series of trees where
cost complexity measure for sub-tree Tₜ is:or
Conclusions
ID: ID_gymx
Number of Columns: 2
Largest Column: standard
Strengths:
• Simple configuration (doesn't have too many configuration parameters);
• Compared to other algorithms decision trees requires less effort for data preparation
during pre-processing.
• A decision tree does not require normalization of data.
• A decision tree does not require scaling of data as well.
• Missing values in the data also do NOT affect the process of building a decision tree to
any considerable extent.
• A Decision tree model is very intuitive and easy to explain to technical teams as well as
stakeholders.
--- column-end ---
Weaknesses:
• Inadequate for problems characterized by many interactions between attributes;
• Does not avoid replicas of subtrees;
• A small change in the data can cause a large change in the structure of the decision tree
causing instability.
• For a Decision tree sometimes calculation can go far more complex compared to other
algorithms.
• Decision tree often involves higher time to train the model.
--- end-multi-column