T2
Models/Techniques learned:
- Random Forest
- Bagging
- AdaBoost
- Neural Networks
- Linear Regressian
- Logistic Regressian
- Naive Bayes
- Classification and Regression Tree (CART)
- K-nearest Neighbour (kNN)
- k-Means
- k-Medias
- ganhar capacidades e conhecimentos
- criar uma linha de raciocínio para resolver problemas
- memorizar
- reconhecer erros
- corrigir erros
- imitar comportamentos
Aprendizagem Automática / Machine Learning
Paradigma de computação em que a característica essencial do sistema se revela pela sua capacidade de aprender de modo autónomo e independente.
A característica diferenciadora dos algoritmos de Machine Learning é a de que são algoritmos orientados aos dados;
- Um hipotético algoritmo aprenderia o que é um determinado objeto pela definição algorítmica da configuração desse objeto;
- Um algoritmo de Machine Learning aprende sem necessidade de que seja codificada a solução do problema;
- Um algoritmo de Machine Learning aprende a partir de diversos exemplos desse objeto, aprendendo desse modo a identificar esse objeto.
Aprendizagem Simbólica vs Não Simbólica
Aprendizagem Simbólica (AS) refere-se ao facto de todos os passos se basearem em representações simbólicas de leitura humana do problema que utilizam a lógica e a procura para resolver o problema.
ID: ID_ti20
Number of Columns: 2
Largest Column: standard
Vantagem
- O processo de raciocínio pode ser facilmente explicado
- num programa de AS é facil perceber porque é que se chega a uma determinada conclusão e quais foram os passos do raciocínio.
--- column-end ---
Desvantagem
- Para o processo de aprendizagem – as regras e o conhecimento precisam ser codificados à mão
- a Aprendizagem Simbólica está muito confinada ao mundo acadêmico e laboratórios universitários com pouco investimento dos gigantes da indústria
--- end-multi-column
Aprendizagem não Simbólica (AnS) tem como uma das desvantagens o facto de ser difícil compreender como é que o sistema chegou a uma conclusão.
- Isto é particularmente importante quando aplicado a
aplicações críticas, tais como condução autonoma de automóveis, diagnóstico médico, entre outras.
- Em sistemas não simbólicos, como aplicações alimentados por DL, não são aceitáveis decisões de alto risco.
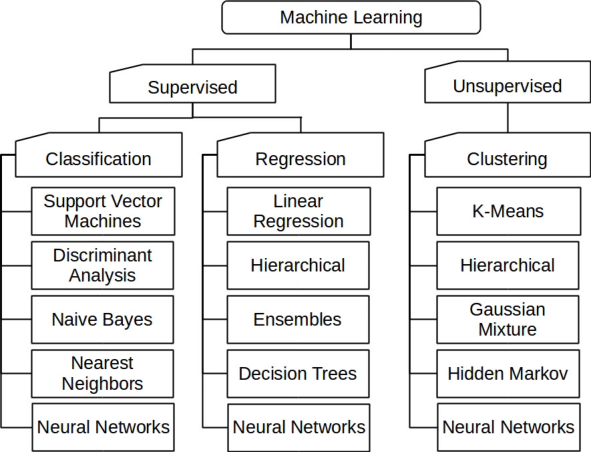
Aprendizagem Supervisionada
Paradigma de aprendizagem em que os casos que se usam para aprender incluem informação acerca dos resultados pretendidos, sendo possível estabelecer uma relação entre os valores pretendidos e os valores produzidos pelo sistema.
- A grande maioria dos algoritmos de Machine Learning usa aprendizagem supervisionada;
- Aprendizagem supervisionada significa que os dados de entrada (x) e os resultados (y), tornam possível que o algoritmo aprenda uma função (f) de mapeamento dos dados nos resultados: y = f ( x );
- "Supervisionada" porque este mapeamento é acompanhado por um algoritmo que supervisiona o processo de aprendizagem;
Normalmente 2 categorias:
- Classificação: quando os resultados são discretos (e.g. preto, branco, cinza…);
- Regressão: quando os resultados são contínuos (e.g. preço, temperatura idade,…
Aprendizagem não Supervisionada
Paradigma de aprendizagem em que não são conhecidos resultados sobre os casos, apenas os enunciados dos problemas, tornando necessário a escolha de técnicas de aprendizagem que avaliem o funcionamento interno do sistema.
- A aprendizagem não supervisionada significa que existem dados de entrada (x) mas não existem os correspondentes resultados;
- O objetivo deste tipo de aprendizagem é o de modelar a estrutura ou a distribuição dos dados do problema;
Normalmente 2 categorias:
- Segmentação (clustering): quando se pretende organizar os dados em grupos coerentes (agrupar clientes que compram produtos biológicos);
- Redução (reduction): reduzir o número de características de um conjunto de dados ou decompor o conjunto de dados em múltiplos componentes;
- Associação: quando se pretende conhecer regras que associem o comportamento demonstrado pelos dados (pessoas que compram produtos biológicos não compram produtos de charcutaria)
Aprendizagem por Reforço
Paradigma de aprendizagem que, apesar de não ter informação sobre os resultados pretendidos, permite efetuar uma avaliação sobre se os resultados produzidos são bons ou maus.
- Algoritmos de Reinforcement Learning usam técnicas de auto-alimentação de sinais, com vista a melhorar os resultados, por influência da noção de recompensa/penalização;
- Não se pode comparar com Aprendizagem Supervisionada uma vez que a “avaliação” dos resultados não é dada por um supervisor;
- Também não se pode considerar Aprendizagem não Supervisionada, uma vez que não existe ausência absoluta de informação sobre os resultados;
A aprendizagem dá-se pela capacidade de crítica sobre os próprios resultados produzidos pelo algoritmo;
- Q-Learning: assume que está a seguir uma política ótima e usa-a para atualização dos valores das ações;
- SARSA: considera a política de controlo que está a ser seguida e atualiza o valor das ações.
- Aprendizagem Automática
- Classificação
- Classificação de imagem
- Fidelização de clientes
- Diagnóstico
- Deteção de fraude
- Regressão, exemplos:
- Crescimento populacional
- Previsão de mercados
- Previsão metereológica
- Esperança média de vida
- Aprendizagem não supervisionada
- Redução
- Visualização (Big Data)
- Compreensão de significados
- Descoberta de Estruturas
- Seleção de atributos
- Segmentação
- Segmentação de clientes
- Marketing
- Sistemas de recomendação
- Aprendizagem por reforço
- Aquisição de aptidões
- Navegação de robots
- Decisões em tempo real
- Tarefas de aprendizagem
- Jogos com IA
Metodologias
- Permite que os projetos sejam replicados;
- Apoia no planeamento e gestão do projeto;
- Incentiva as melhores práticas e ajuda a obter melhores resultados.
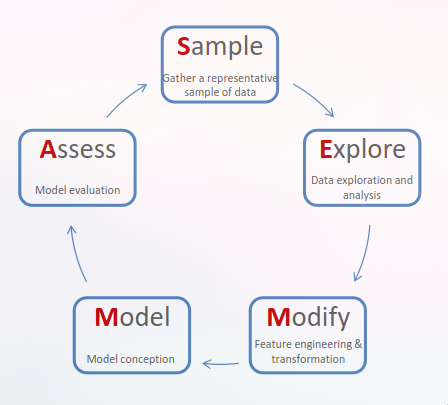
SEMMA
- S - Sample: Gather a representative sample of data
- E - Explore: Data exploration and analysis
- M - Modify: Feature engineering and transformation
- M - Model: Model conception
- A - Assess: Model evaluation
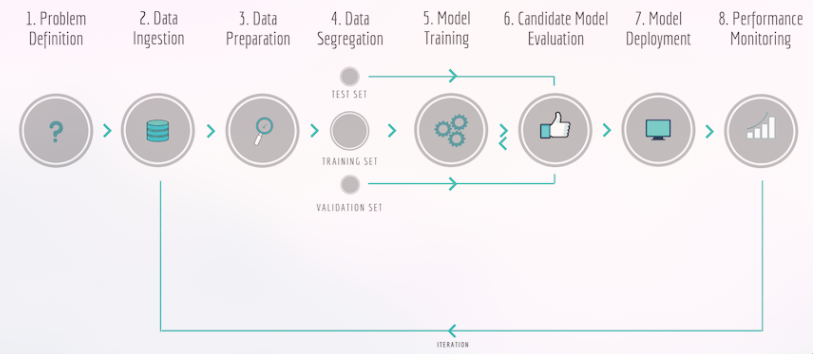
CRISP-DM: Cross Industry Process for Data Mining

Fluxo de Aprendizagem Automática
- Problem Definition
- Data Ingestion
- Data Preparation
- Data Segregation
- Model Training
- Candidate Model Evaluation
- Model Deployment
- Performance Monitoring