PL - Aula 4
4 de Outubro 2023 - #CP
Ex. 2
a) Limitações vetoriais
A -> consecutive elements in a row -> consecutive access in the vector
C -> same element
B -> consecutive elements in a collumn
Não vai ser vetorizável.
b) Enable vectorization
result of change cycles to i, k , j :
A -> same element
C -> consecutive elements in a row -> consecutive access in the vector
B -> consecutive elements in a row -> consecutive access in the vector
i k j
0 0 1
Vai ser vetorizável.
128b
8B -> 64b
2 elements
Without vectorization:
With vectorization:
Estimated: ( n^3 / 2 )* 8
c)Measure and analyze results
| N | Version | Time | CPI | #I |
|---|---|---|---|---|
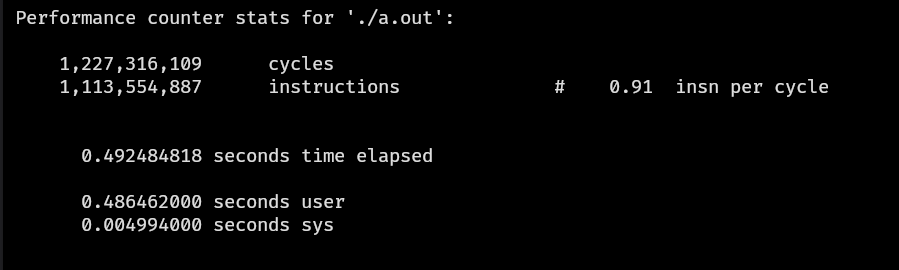
| 512 | base_v() | 0.492484818 | 0.91 | 1113554887 |
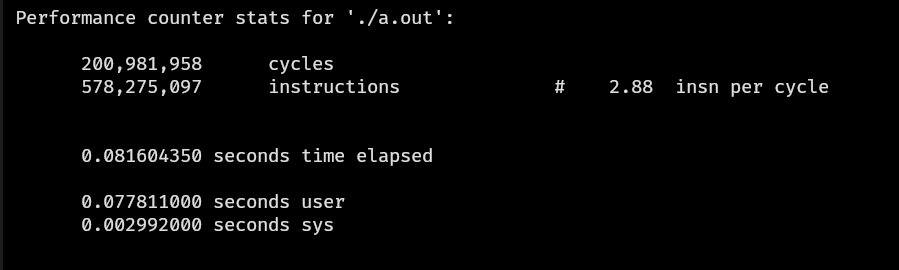
| 512 | vect() | 0.081604350 | 2.88 | 578275097 |
module load gcc/9.3.0
gcc -O2 -ftree-vectorize -msse4 mmult.c
srun --partition=cpar perf stat -e cycles,instructions ./a.out
d) Vectorization fine-tuning
Ganhos de 4 vezes mais.
Ex. 3
a) Peak Performance
2 operações em FP
4 elementos de cada vez em cada ciclo
2.5 GHz -> 2.5 billion cycles per second
conclusion: 20 GFlop/s
AVX -> 256b -> 4 doubles
machine is superscalar with 2 FOP units
4x2= 8 double-perations
freq = 2.5 GHz
8x2.5= 20 GFlop/s
^ cpu limitiation
b)
peak with vectorization: continuous 20 GFlop/s
peak without vectorization: continuous 5 GFlop/s
memory bandwith limitation: see alinea d)
real achievable performance:see alinea c)
measured performance:
d) Memory bandwidth limitation
1 FOP -> 2B
| GFlop/s | Flop/Byte |
|---|---|
| 0.125 | 2.5 |
| 0.25 | 5 |
| 0.5 | 10 |
| 1 | 20 |
| 2 | 40 |
| 4 | 80 |
| 8 | 160 |
c)
2 FOP (operações vírgula flutuante) -> 2 doubles (16B)
1 operation/8B -> 0.125
| GFlop/s | Flop/Byte |
|---|---|
| 2.5 | 0.125 |